



How to Avoid the Sourcing Data Swamp


You had the best intentions when you bought Pitchbook, Sourcescrub, Harmonic, etc. You were expecting immediate insights when you signed up for a modern CRM like Attio or Affinity. You told yourself and your GPs that all you needed to do was hire a data scientist, spin up a Snowflake instance, slap an LLM on top of it, and then a herd of embryonic unicorns would prance onto your investors’ iPhone screens (because name one investor who still uses a laptop these days). You thought this was the roadmap to put your firm on the cutting edge of data-driven deal sourcing.
But that’s not what happened.
You quickly realized that unifying all these data feeds was really hard and time-consuming, and that it would take more than just you and your data scientist to do it well. (Assuming your data scientist doesn’t quit first.) The project you thought would cost a couple hundred grand is looking closer to a couple million, months are stretching into years, and the more you scope out the task ahead, the longer the road to ROI feels.
How did you find yourself sinking into a data swamp? Let’s break it down.
Third-party sourcing data is great, but it’s a mess to put it all together.
You know how there are ticker symbols and CUSIPs and ISINs in the public market that identify a public company and unify all sorts of data about it? Well, that hasn’t been invented in the private market yet. None of your data feeds talk to one another, and that fancy CRM you have that claims to unify 3rd party data with your first party data has lame APIs. Even worse, CRMs use email addresses as identifiers, which means you probably have the same founder associated with like four different email addresses, because serial entrepreneurs.
Instead of focusing on identifying the next founder your firm should be meeting, you’re spending your time digging through email data figuring out whether your team emailed the founder of the seed round you missed. (How many personal emails can one person have?) You’re looking through your data feeds to figure out whether that company you talked to last year changed their name, or whether its founder started a new company.
One of the reasons you’re in this mess is because you have no way of implementing entity resolution, which tells you that a company in Pitchbook is the same company in Harmonic is the same company is Affinity, etc. Building an entity resolution engine is not a “one data scientist” kind of project. It’s a “many data scientist, many data engineer, many quarter” project that will burn through your engineering budget and distract your team from surfacing the next great start-ups for your firm.
The false choice of Build vs Buy.
The natural impulse for any ambitious data organization is to boot-strap and build everything in house. “If we own it, it’ll be our edge,” right? This was certainly the mindset back in 2022, when every private fund seemed to think the right thing to do was to go out and buy Snowflake or Databricks and PowerBI or Looker, spend millions of dollars to buy every dataset on the market, and build every piece of the data stack they needed to confidently tell themselves “we are a data-driven firm now.”
This isn’t a terrible strategy if you’re a16z, but for everyone else it’s misguided, because instead of being data-driven, you’re data-clogged.
You’re spending valuable time and money on infrastructure that feels more like plumbing than alpha-generating, when you should be sourcing new companies and finding signals to bring to your investors. Let’s be honest: your LPs are not paying you for merging together founder email addresses, and in the meantime your firm is at risk of missing the next great deal.
Why spend your time and money building infrastructure when what you should be focusing on is how quickly you can turn your data budget into ROI?
Foresight solves these problems out of the box.
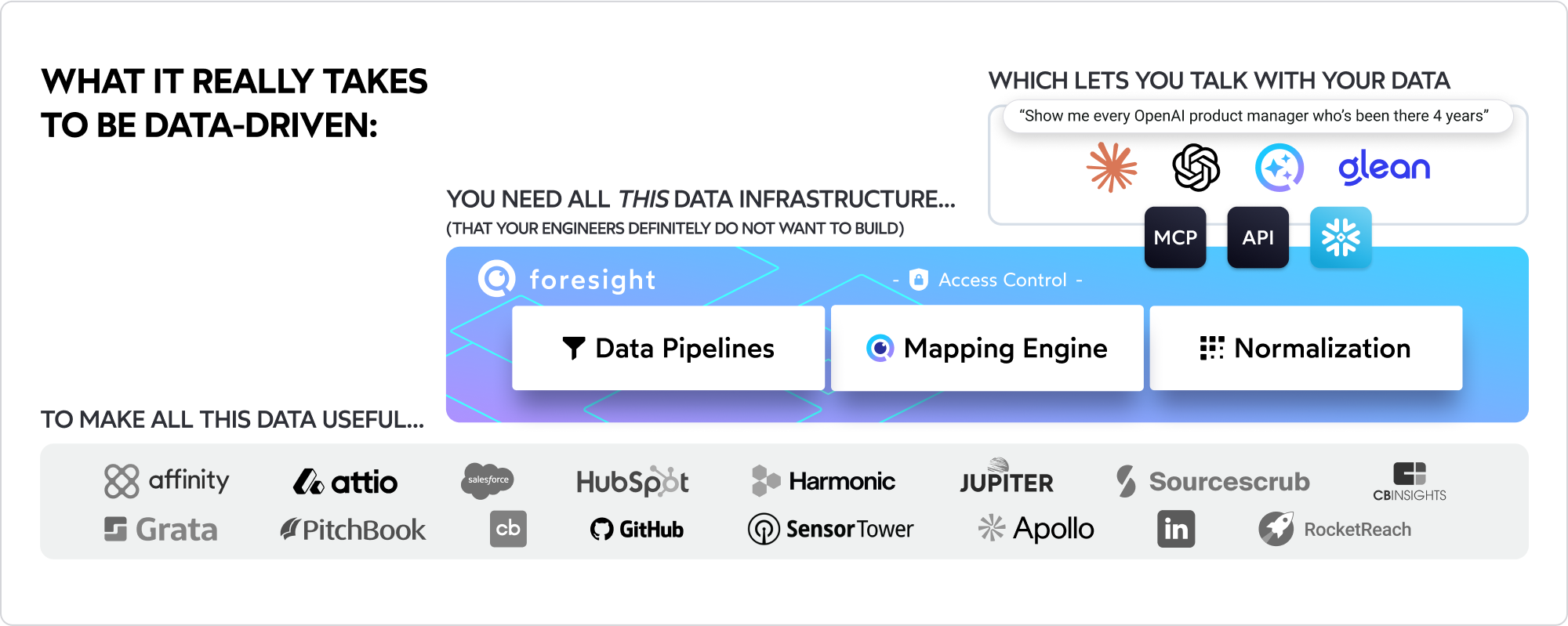
Instead of spending months building your own entity resolution engine, Foresight’s proprietary “data mesh” provides your team a clean data foundation within days. That means you can focus on developing your sourcing algorithms, tracking founders and companies with the confidence you aren’t missing any signals, and getting to higher ROI on your team’s budget, faster.
Buy your infra, build your alpha.
We believe that your firm’s alpha isn’t in building and maintaining the infrastructure that every data team at every investment firm needs. Our expertise is in bringing all your data together - your firm’s alpha is in what your investors decide to do with it. Every dollar and every hour you spend debugging an API connector, merging a duplicate, or mapping companies to their URLs is time and money you should be spending on supporting your firm putting its capital to work.
With Foresight, you can transform that data swamp into a freshwater lake - with clear line of sight to the returns on the shore. Email adam@foresightdata.com to learn more.




